I’m a senior staff engineer at MongoDB at MongoDB Research. I live and climb in New Paltz, NY. I wrote Motor, the async MongoDB Python driver, and I’ve contributed to MongoDB, the MongoDB C Driver, PyMongo, asyncio, Python, and Tornado. I studied at the International Center for Photography and I practice at the Village Zendo and New Paltz Zen Center. You can read more about me or find me on Twitter or Mastodon.
Latest Articles
- Jyakuen's Shuso Hossen
 March 24, 2024. A ceremony at the Village Zendo. Jyakuen gave her first dharma talk and became a senior Zen student.
March 24, 2024. A ceremony at the Village Zendo. Jyakuen gave her first dharma talk and became a senior Zen student.
- Monks at Holy Cross
 An Anglican Benedictine monastery in the Hudson Valley.
An Anglican Benedictine monastery in the Hudson Valley.
- Bodhisattvas Always Smile
 We vow to bear witness to the world's suffering, but there's no reason to be gloomy about it. Let's be cheerful bodhisattvas!
We vow to bear witness to the world's suffering, but there's no reason to be gloomy about it. Let's be cheerful bodhisattvas!
- Ordination at Christ Episcopal
 March 5, 2024. An ordination ceremony for Emily Carter at Christ Episcopal Church in Poughkeepsie.
March 5, 2024. An ordination ceremony for Emily Carter at Christ Episcopal Church in Poughkeepsie.
- Climbing in Puerto Rico
 February 2024. Photos of my friends sport-climbing on the limestone crags near San Juan.
February 2024. Photos of my friends sport-climbing on the limestone crags near San Juan.
… More Articles
Selected Articles
- Psilocybin session at Johns Hopkins
 Photos from the Center for Psychedelic and Consciousness Research in Baltimore.
Photos from the Center for Psychedelic and Consciousness Research in Baltimore.
- Paper Review: E-Store, P-Store, and Elastic Database Systems
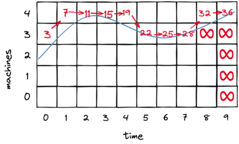 A PhD thesis and two papers about reactive and predictive autoscaling.
A PhD thesis and two papers about reactive and predictive autoscaling.
- The MongoDB Stable API
 For MongoDB 5.0, I designed a new Stable API that permits you to upgrade without code changes.
For MongoDB 5.0, I designed a new Stable API that permits you to upgrade without code changes.
- How To Understand Non-Self: Buddhism And Conway's Game Of Life
 John Conway's Game of Life is a math puzzle that gives us insights into the Buddha's teaching of anatman.
John Conway's Game of Life is a math puzzle that gives us insights into the Buddha's teaching of anatman.
- Paper review: Paxos vs Raft
 Which consensus algorithm will win?
Which consensus algorithm will win?
- Two attempts to compare a TLA+ spec with a C++ implementation
 At MongoDB we tried two methods to test that a spec matches the code: one worked, one didn't. We explain our results in a VLDB 2020 paper.
At MongoDB we tried two methods to test that a spec matches the code: one worked, one didn't. We explain our results in a VLDB 2020 paper.
- Meditation at Home
 Photographs of Village Zendo members in early 2020.
Photographs of Village Zendo members in early 2020.
- Reading A Journal of the Plague Year in New York
 Daniel Defoe's account of London in 1665 is eerily like New York in 2020.
Daniel Defoe's account of London in 1665 is eerily like New York in 2020.
- You Look So Zen
 On a visit to some Buddhists incarcerated on a jail barge, I had to improvise how to practice Zen, just like we always have to improvise our practice.
On a visit to some Buddhists incarcerated on a jail barge, I had to improvise how to practice Zen, just like we always have to improvise our practice.
- PyGotham 2019's ASL and Live Captioning Playbook
 Here's what we did for Deaf and hard-of-hearing accessibility, in detail. I hope this recap can be a playbook for future conferences.
Here's what we did for Deaf and hard-of-hearing accessibility, in detail. I hope this recap can be a playbook for future conferences.
- Five Ways to Establish a Rock-Solid Meditation Habit
 Meditation can transform your life, but it only works if you sit regularly. You can establish a strong, serious practice following these five methods.
Meditation can transform your life, but it only works if you sit regularly. You can establish a strong, serious practice following these five methods.
- The Meteor
 What if you knew you had 30 minutes to live? Would you want to be awakened?
What if you knew you had 30 minutes to live? Would you want to be awakened?
- Ordinary Zen
 A portrait series of Zen practitioners.
A portrait series of Zen practitioners.
- Optimizing MongoDB Compound Indexes
 How to find the best multicolumn index for a complex query.
How to find the best multicolumn index for a complex query.
Projects
- Motor: A full-featured non-blocking MongoDB driver for Tornado.
- PyMongo: I help maintain the standard MongoDB driver for Python.
- A queue implementation for
asyncioin the Python 3.4 standard library. - Portraits of Lower East Siders, residents of transitional housing, and American Buddhists.